Техническая документация
- Таблицы по окнам возможностей
- staffRequests
- staffRequestsReserves
- staffRequestsDeclines
- staffRequestsEvents
- staffRequestsSubscriptions
- staffRequestsResponses
- staffRequestsOffers
- Предиктивная аналитика
- Описание прогнозной модели
- Работа с данными для прогнозов
- Запросы для составления прогнозов
- Расчёт требуемого количества сборщиков и курьеров
- Аналитика сборки по прошедшим дням
- Аналитика сборки по будущим дням
- Аналитика курьеров по прошедшим дням
- Аналитика курьеров по будущим дням
- Таблица плановых и фактических курьеров
Таблицы по окнам возможностей
staffRequests
В базе данных Ally информация об окнах возможностей хранится в таблице staffRequests.
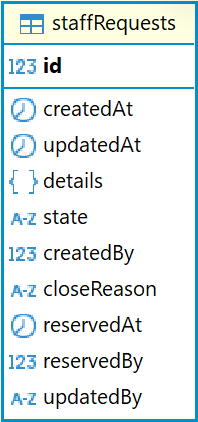
Описание полей таблицы staffRequests:
|
Поле |
Описание |
|
id |
Уникальный идентификатор заявки |
|
createdAt |
Дата и время создания заявки |
|
updatedAt |
Дата и время последнего изменения заявки |
|
details |
Подробная информация об окне возможностей в которую входит:
|
|
state |
Текущий статус заявки |
|
createdBy |
Идентификатор пользователя, создавшего заявку (указывается userId пользователя) |
|
closeReason |
Причина закрытия или удаления окна |
|
reservedAt |
Дата и время резервирования окна. Устаревшее поле, вместо него используется таблица staffRequestsReserves |
|
reservedBy |
Идентификатор пользователя, зарезервировавшего окно (указывается userId пользователя). Устаревшее поле, вместо него используется таблица staffRequestsReserves |
|
updatedBy |
Идентификатор пользователя, последним изменившего заявку |
staffRequestsReserves
В базе данных Ally резервы окон возможностей хранятся в таблице staffRequestsReserves.
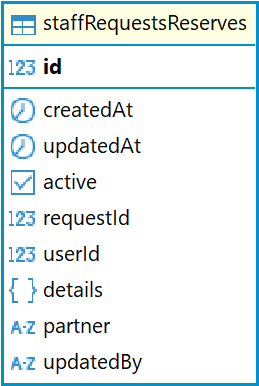
Описание полей таблицы staffRequestsReserves:
|
Поле |
Описание |
|
id |
Уникальный идентификатор |
|
createdAt |
Дата и время создания записи |
|
updatedAt |
Дата и время последнего обновления записи |
|
active |
Статус резерва (активен или нет) |
|
requestId |
Идентификатор окна (ссылается на таблицу staffRequests) |
|
userId |
Идентификатор пользователя |
|
details |
Дополнительные данные |
|
partner |
Название контрагента для резерва |
|
updatedBy |
Идентификатор пользователя, который последний раз отредактировал запись |
staffRequestsDeclines
В базе данных Ally отклоненные окна возможностей сохраняются в таблице staffRequestsDeclines.
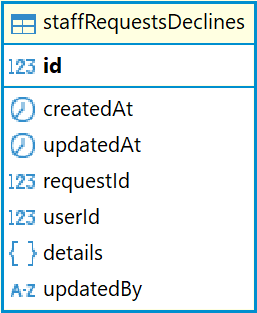
Описание полей таблицы staffRequestsReserves:
|
Поле |
Описание |
|
id |
Уникальный идентификатор |
|
createdAt |
Дата и время создания записи |
|
updatedAt |
Дата и время последнего обновления записи |
|
requestId |
Идентификатор окна (ссылается на таблицу staffRequests) |
|
userId |
Идентификатор пользователя |
|
details |
Дополнительные данные |
|
updatedBy |
Идентификатор пользователя, который последний раз отредактировал запись |
staffRequestsEvents
В базе данных Ally связь между окном возможностей и выходом хранится в таблице staffRequestsEvents.
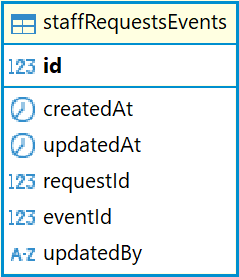
Описание полей таблицы staffRequestsEvents:
|
Поле |
Описание |
|
id |
Уникальный идентификатор |
|
createdAt |
Дата и время создания записи |
|
updatedAt |
Дата и время последнего обновления записи |
|
requestId |
Идентификатор окна (ссылается на таблицу staffRequests) |
|
eventId |
Идентификатор выхода (ссылается на таблицу events) |
|
updatedBy |
Идентификатор пользователя, который последний раз отредактировал запись |
staffRequestsSubscriptions
В базе данных Ally информация о подписках на окна возможностей в мобильном приложении хранится в таблице staffRequestsSubscriptions.
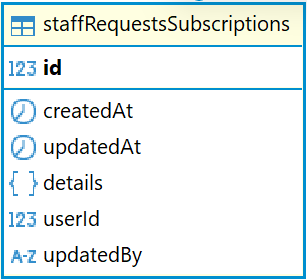
Описание полей таблицы staffRequestsSubscriptions:
|
Поле |
Описание |
|
id |
Уникальный идентификатор |
|
createdAt |
Дата и время создания записи |
|
updatedAt |
Дата и время последнего обновления записи |
|
details |
Дополнительные данные |
|
userId |
Идентификатор пользователя |
|
updatedBy |
Идентификатор пользователя, который последний раз отредактировал запись |
staffRequestsResponses
В базе данных Ally отклики на окна возможностей хранятся в таблице staffRequestsResponses.
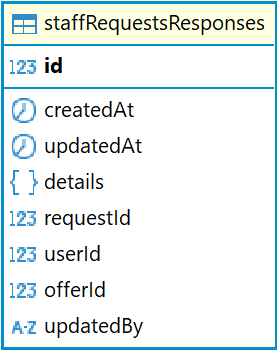
Описание полей таблицы staffRequestsResponses:
|
Поле |
Описание |
|
id |
Уникальный идентификатор |
|
createdAt |
Дата и время создания записи |
|
updatedAt |
Дата и время последнего обновления записи |
|
details |
Дополнительные данные, комментарии |
|
requestId |
Идентификатор окна (ссылается на таблицу staffRequests) |
|
userId |
Идентификатор пользователя |
|
offerId |
Идентификатор оффера (ссылается на таблицу staffRequestsOffers). Устаревшее поле, не используется |
|
updatedBy |
Идентификатор пользователя, который последний раз отредактировал запись |
staffRequestsOffers
staffRequestsOffers - устаревшая таблица, которая уже не используется.
Предиктивная аналитика
Описание прогнозной модели
Прогнозная модель используется для оценки заказов, трудоемкости и распределения ресурсов. Модели и скрипты размещены на сервере izb-ally-nodered02 (IP: 10.1.241.244). Скрипты написаны на Python с использованием библиотеки ENTA.
Скрипты и команды для работы с моделью
python3.10 main.py --help
Usage: main.py [OPTIONS] COMMAND [ARGS]...
Options:
--help Show this message and exit.
Commands:
copy copy time_series from one DB to another
fit Fits model with collected lines from DB
forecast Makes forecast for the next 7 days and saves it to DB
test Evaluates forecast metrics
view Prints one segment used for forecast
Модель и обучение
Наилучшие результаты показывает модель CatBoost. Перед использованием модель необходимо обучить. После обучения она применяется для прогнозов. Данные для обучения поступают из различных источников, результаты сохраняются в гипертаблицу time_series.
Источники данных
- Погода:
- Исторические данные (с 2005 года) и ежедневные обновления загружаются с rp5.ru в таблицы weather и weather_stations с помощью скрипта rp5_weather (настраивается через файл static/cities.txt с списком метеостанций).
- Актуальный прогноз погоды загружается ежедневно с api.met.no через Node-RED в таблицу weather.
- Календарь: Учитываются данные производственного календаря из таблицы calendar и православных праздников. Включение мусульманских праздников не улучшило точность.
- База данных ВкусВилл
Параметры прогноза
Прогноз строится на заданное количество дней вперед с различной дискретизацией (шагом по времени).
Прогноз для последней мили (сборка и доставка)
Строится с шагом 1 час на 14 дней вперед.
- Обычный прогноз: Основан на данных о сборке и доставке, где заказы привязаны к торговой точке (ТТ). Данные загружаются из MS SQL в БД Ally через Node-RED.
- Зональный прогноз: Учитывает данные о сборке/доставке и статистику распределения адресов по геозонам ТТ. На основе геозон формируются сводные буферы с вероятностями выполнения заказов (на основе статистики за 7 дней). История заказов сопоставляется с текущими геозонами для обучения модели, что позволяет прогнозировать для новых ТТ с ограниченной историей.
Прогноз для розницы
Строится с шагом 1 день на 21 день вперед. Основан на оценке трудоемкости, загружаемой во временной ряд 51 через Node-RED.
Работа с данными для прогнозов
Исходные данные извлекаются из базы данных ВкусВилл (таблицы: Report.[report_zakaz_tbl], [GeoReports].[Analytics].[EffectiveZonesOnlineServices] и [Geo].[geo].[tt]), а также с внешних источников: API met.no и rp5.ru.
Собранные данные сохраняются в следующих таблицах:
- vv_orders_ts — временные ряды заказов;
- test_vv_points — тестовые точки;
- weather — данные о погоде;
- weather_stations — информация о метеостанциях;
- calendar — календарные данные.
Прогнозная модель CatBoost извлекает данные из указанных таблиц и выполняет их обработку.
Результаты обработки, включая прогнозы модели CatBoost, сохраняются в таблице time_series. На основе этих результатов производятся дальнейшие расчеты для аналитики.

Получение данных о заказах
Для получения данных о заказах составляется отчет по заказам с фильтрацией по дате заказа и наличию даты поставки.
Источником получения данных служит таблица Report.[report_zakaz_tbl]
Запрос извлекает данные о заказах из таблицы отчетов за указанный период времени. Запрос фокусируется на заказах, где дата заказа находится в заданном диапазоне, и дата поставки не является NULL. Дополнительно вычисляется поле с датой поставки, увеличенной на 15 минут.
Текст запроса
Ниже представлен запрос для получения информации о заказах:
SELECT
id_order as id,
ShopNo as shopno,
order_type,
gettype,
date_order,
date_supply,
date_supply_untill,
date_posted,
date_collect_start,
date_collected,
date_delivery_start,
date_delivered,
sum_paid,
sum_paid_coupon,
count_pos,
latitude,
longitude,
client_type,
order_weight,
delivery_hottime,
collecting_await_dur,
collecting_dur,
delivery_await_dur,
delivery_dur,
completed_agg,
distance,
DATEADD(Minute, 15, date_supply) as date_supply_vv
FROM Report.[report_zakaz_tbl] rzt (NOLOCK)
WHERE date_order BETWEEN '{{payload.from}}' AND '{{payload.to}}'
AND date_supply IS NOT NULLПоля запроса
Запрос возвращает 27 полей. Ниже приведена таблица с описаниями:
| Поле SELECT | Исходное поле | Тип данных |
| id | id_order | INT |
| shopno | ShopNo | INT |
| order_type | order_type | TinyInt |
| gettype | gettype | TinyInt |
| date_order | date_order | DateTime |
| date_supply | date_supply | DateTime |
| date_supply_untill | date_supply_untill | DateTime |
| date_posted | date_posted | DateTime |
| date_collect_start | date_collect_start | DateTime |
| date_collected | date_collected | DateTime |
| date_delivery_start | date_delivery_start | DateTime |
| date_delivered | date_delivered | DateTime |
| sum_paid | sum_paid | FLOAT |
| sum_paid_coupon | sum_paid_coupon | FLOAT |
| count_pos | count_pos | SmallInt |
| latitude | latitude | Decimal(19,16) |
| longitude | longitude | Decimal(19,16) |
| client_type | client_type | NVarChar(100) COLLATE Cyrillic_General_CI_AS |
| order_weight | order_weight | Decimal(15,3) |
| delivery_hottime | delivery_hottime | DateTime |
| collecting_await_dur | collecting_await_dur | INT |
| collecting_dur | collecting_dur | INT |
| delivery_await_dur | delivery_await_dur | INT |
| delivery_dur | delivery_dur | INT |
| completed_agg | completed_agg | INT |
| distance | distance | Real |
| date_supply_vv | date_supply | (вычисляемое) |
Фильтры запроса
В запросе присутствуют 2 фильтра:
- date_order BETWEEN '{{payload.from}}' AND '{{payload.to}}' — Фильтр по дате заказа. Включает заказы, где дата заказа >= '{{payload.from}}' и <= '{{payload.to}}'.
- date_supply IS NOT NULL — Исключает заказы без указанной даты поставки.
Вычисляемые поля
В запросе есть вычисляемое поле:
- DATEADD(Minute, 15, date_supply) as date_supply_vv — Функция SQL Server для добавления 15 минут к полю date_supply.
Получение данных о геозонах
Для получения данных о геозонах составляется отчет по зонам с фильтрацией по магазинам.
Источником получения данных служит таблицы [GeoReports].[Analytics].[EffectiveZonesOnlineServices] и [Geo].[geo].[tt]
Запрос объединяет данные из двух таблиц для получения информации о зонах, услугах и временных интервалах.
Текст запроса
Ниже представлен запрос для получения информации о заказах:
SELECT
tt.N AS id_tt,
id_online_service,
id_poly,
date_add,
geo,
payway,
time_start,
time_end
FROM [GeoReports].[Analytics].[EffectiveZonesOnlineServices] (NOLOCK) z
JOIN [Geo].[geo].[tt] tt ON tt.id_TT = z.id_tt
WHERE tt.name_TT LIKE '%ДС[_]%Поля запроса
Запрос возвращает 8 полей. Ниже приведена таблица с описаниями:
| Поле SELECT | Исходное поле | Тип данных |
| id_tt | tt.N | |
|
id_online_service |
id_online_service |
|
|
id_poly |
id_poly |
|
|
date_add |
date_add |
|
|
geo |
geo |
|
|
payway |
payway |
|
|
time_start |
time_start |
|
|
time_end |
time_end |
Фильтры запроса
В запросе присутствуют 2 фильтра:
- INNER JOIN на tt.id_TT = z.id_tt — Это объединяет записи только если есть совпадение по идентификатору точки (id_tt). Если в z нет соответствующей записи в tt, она не попадет в результат.
- WHERE tt.name_TT like '%ДС[_]%' — Фильтр по имени точки (магазина) в таблице tt.
Таблицы хранения полученных данных
Исходные данные, используемые для построения прогноза, размещены в следующих таблицах:
- vv_orders_ts — гипертаблица с информацией о заказах. Включает поля, заполняемые на основе исходной таблицы Report.[report_zakaz_tbl], а также ряд дополнительных полей.
- test_vv_points — географические зоны, связанные с торговыми точками (ТТ).
- weather — данные о погоде, загруженные из сервиса https://api.met.no.
- weather_stations — погодные станции с сервиса rp5.ru. Применялись для загрузки исторических метеоданных.
- calendar — табель-календарь, заполняемый посредством системы репликации.
Кроме того, на базе этих таблиц создаются материализованные представления:
- vv_orders_ts_hash_hourly — заказы в географической зоне за определенный час, исключая заказы с типом gettype = 6 (доставка через Яндекс).
- vv_lines_ts_hash_hourly — количество собранных строк для географической зоны за конкретный час.
Ниже приведено описание этих таблиц и представлений, в которым перечислены поля использующиеся для составления прогноза.
vv_orders_ts
| Поле | Тип данных |
| id | int4 |
| shopno | int4 |
| order_type | int4 |
| gettype | int4 |
| date_order | timestamp |
| date_supply | timestamp |
| date_supply_untill | timestamp |
| date_posted | timestamp |
| date_collect_start | timestamp |
| date_collected | timestamp |
| date_delivery_start | timestamp |
| date_delivered | timestamp |
| sum_paid | float8 |
| sum_paid_coupon | float8 |
| count_pos | int2 |
| latitude | numeric(19, 16) |
| longitude | numeric(19, 16) |
| client_type | varchar(100) |
| order_weight | numeric(15, 3) |
| delivery_hottime | timestamp |
| collecting_await_dur | int4 |
| collecting_dur | int4 |
| delivery_await_dur | int4 |
| delivery_dur | int4 |
| completed_agg | int4 |
| distance | float4 |
| date_supply_vv | timestamp |
| details | jsonb |
| tt_id | int4 |
| geohash | varchar(20) |
test_vv_points
| Поле | Тип данных | Описание |
| geohash | varchar(20) | Геохэш области |
| tt_id | numeric | ИД иорговой точки |
| coeff | int4 |
Вероятность того, что заказ в данной области попадет в данную ТТ. Определяется на основе статистики заказов за предыдущие 3 дня
|
weather
| Поле | Тип данных | Описание |
| weather_station_id | int4 | ИД погодной станции |
| date | timestamp | Время |
| temperature | numeric(3, 1) |
Температура |
| humidity | int4 |
Влажность |
| wind_speed | int4 |
Скорость ветра |
weather_stations
| Поле | Тип данных | Описание |
| id | serial4 | ИД погодной станции |
| active | bool | Признак активности |
calendar
| Поле | Тип данных | Описание |
| id | serial4 | ИД |
| date | date | Дата |
| type | int4 | Тип (2 - суббота, 3 - воскресенье, 4 - предпраздничный день, 5 - праздник) |
vv_orders_ts_hash_hourly
Для составления представления формируется запрос который формирует представление для хранения агрегированных данных о количестве заказов, сгруппированных по геохешу и часовым интервалам. Исключаются заказы с типом получения gettype = 6. Представление обновляется автоматически.
Источником получения данных служит таблица vv_orders_ts.
Текст запроса:
CREATE MATERIALIZED VIEW vv_orders_ts_hash_hourly
WITH (timescaledb.continuous) AS
SELECT
geohash,
time_bucket('1 hour', ts.date_supply_vv) AS bucket,
COUNT(*) AS cnt
FROM vv_orders_ts ts
WHERE ts.gettype != 6
GROUP BY geohash, bucket;Поля запроса:
| Поле | Тип данных | Описание |
| geohash | varchar(20) | |
| bucket | timestamp | |
| cnt | int8 |
vv_lines_ts_hash_hourly
Для составления представления формируется запрос который формирует представление для хранения агрегированных данных о суммарном количестве позиций (строк) в заказах, сгруппированных по геохешу и часовым интервалам.
Источником получения данных служит таблица vv_orders_ts.
Текст запроса:
CREATE MATERIALIZED VIEW vv_lines_ts_hash_hourly
WITH (timescaledb.continuous) AS
SELECT
geohash,
time_bucket('1 hour', ts.date_supply_vv) AS bucket,
SUM(ts.count_pos) AS cnt
FROM vv_orders_ts ts
GROUP BY geohash, bucket;Поля запроса:
| Поле | Тип данных | Описание |
| geohash | varchar(20) | |
| bucket | timestamp | |
| cnt | int8 |
Хранение результатов обработки исходных данных
Данные для прогнозов, сами прогнозы и результаты их анализа хранятся во временных рядах в таблице time_series:
| Поле | Тип данных | Описание |
| id | bigserial | |
| tstamp | timestamptz | |
| type | int4 | Описывает тип данных |
| restaurant_id | int4 | |
| user_id | int4 | |
| value | float8 | Значение прогноза |
| details | jsonb |
Тип прогноза, для которого сформирован результат обработки, определяется значением поля type. Возможные числовые значения поля и их интерпретация приведены ниже. Сформированный прогноз по часам помещается в таблицу под типами 4-7
| type | Описание | Подразделение | Тип | Источник |
| 1 | Данные по доставке | Последняя миля | Исходные данные | Репликатор |
| 2 | Данные по сборке | Последняя миля | Исходные данные | Репликатор |
| 4 | Прогноз доставка | Последняя миля | Прогноз | Python |
| 5 | Прогноз сборка | Последняя миля | Прогноз | Python |
| 6 | Прогноз по геозонам доставка | Последняя миля | Прогноз | Python |
| 7 | Прогноз по геозонам сборка | Последняя миля | Прогноз | Python |
| 51 | Оценка трудоемкости розница | Розница | Исходные данные | Node-RED |
| 52 | Прогноз суммарной трудоемкости Розница | Розница | Прогноз | Python |
| 53 | Прогноз трудоемкости кассиров Розница | Розница | Прогноз | Python |
| 55 | Факт суммарной выработки Розница | Розница | Аналитика | pgAgent |
| 56 | Факт выработки кассиров Розница | Розница | Аналитика | pgAgent |
| 154 | Курьеры факт | Последняя миля | Аналитика | Node-RED |
| 155 | Курьеры план | Последняя миля | Аналитика | Node-RED |
| 156 | Курьеры прогноз | Последняя миля | Аналитика | Node-RED |
| 157 | Заказы план | Последняя миля | Аналитика | Node-RED |
Запросы для составления прогнозов
Данные о доставке и сборке используются в качестве основного прогнозируемого ряда, в то время как остальные (погода, праздники) в качестве регрессионных данных.
Зональный прогноз доставки
Для зонального прогноза доставки извлекаются и агрегируются данные рассчитываемые как сумма количества заказов (cnt), умноженного на коэффициент из геоточки (coeff), сгруппированных по идентификатору торговой точки (tt_id) и часовому интервалу (bucket).
Ниже представлен запрос который делает все это и объединяет данные о заказах с географическими точками для анализа по сегментам (торговым точкам или зонам) в заданном диапазоне дат:
SELECT
h.bucket AS timestamp,
vp.tt_id AS segment,
SUM(cnt * coeff) AS target
FROM vv_orders_ts_hash_hourly h
JOIN test_vv_points vp ON vp.geohash = h.geohash
WHERE bucket BETWEEN '{from_date}' AND '{to_date}'
GROUP BY vp.tt_id, h.bucket;Запрос берет значения из:
- vv_orders_ts_hash_hourly — представление которое содержит агрегированные данные о количестве заказов по геохешу и часам.
- test_vv_points — таблица, содержащая географические зоны, связанные с торговыми точками.
Запрос формирует следующие поля:
| Поле в SELECT | Исходное поле | Описание |
| timestamp | h.bucket | Временной интервал, начало часа для агрегации данных о заказах. |
| segment | vp.tt_id | Идентификатор торговой точки, к которой привязан geohash. |
| target | (Вычисляемое) | Сумма (cnt * coeff), где cnt — количество заказов, coeff — коэффициент из геоточки. |
Зональный прогноз сборки
Для зонального прогноза сборки извлекаются и агрегируются данные рассчитываемые как сумма количества строк в заказах (cnt), умноженного на коэффициент (coeff), сгруппированных по идентификатору торговой точки (tt_id) и часовому интервалу (bucket).
Ниже представлен запрос который который делает все это и объединяет данные о строках заказов с географическими точками для зонального анализа в заданном диапазоне дат.
SELECT
h.bucket AS timestamp,
vp.tt_id AS segment,
SUM(cnt * coeff) AS target
FROM vv_lines_ts_hash_hourly h
JOIN test_vv_points vp ON vp.geohash = h.geohash
WHERE bucket BETWEEN '{from_date}' AND '{to_date}'
GROUP BY vp.tt_id, h.bucket;Запрос берет значения из:
- vv_lines_ts_hash_hourly — представление которое содержит агрегированные данные о количестве заказов по геохешу и часам.
- test_vv_points — таблица, содержащая географические зоны, связанные с торговыми точками.
Запрос формирует следующие поля:
| Поле в SELECT | Исходное поле | Описание |
| timestamp | h.bucket | Временной интервал, начало часа для агрегации данных о заказах. |
| segment | vp.tt_id | Идентификатор торговой точки, к которой привязан geohash. |
| target | (Вычисляемое) | Сумма (cnt * coeff), где cnt — количество строк в заказах, coeff — коэффициент из геоточки. |
Данные о погоде
В прогнозах используются данные о погоде, такие как температура, влажность и скорость ветра из активных погодных станций в заданном диапазоне дат.
Ниже представлен запрос данных о погоде с дополнением последними значениями на конечную дату.
WITH t AS (
SELECT
w.weather_station_id AS station_id,
w.date,
w.temperature,
w.humidity,
w.wind_speed,
ROW_NUMBER() OVER (PARTITION BY w.weather_station_id ORDER BY w.date DESC) AS rn
FROM weather w
JOIN weather_stations st ON st.id = w.weather_station_id
WHERE st.active AND date BETWEEN '{from_date}' AND '{to_date}'
)
SELECT
station_id,
date,
temperature,
humidity,
wind_speed
FROM t
UNION
SELECT
station_id,
'{to_date}',
temperature,
humidity,
wind_speed
FROM t
WHERE t.rn = 1
ORDER BY station_id, date;Запрос берет значения из:
-
weather — содержит исторические данные о погоде по станциям и датам.
-
weather_stations — содержит информацию о погодных станциях.
Запрос формирует следующие поля:
| Поле в SELECT | Исходное поле | Описание |
| station_id | w.weather_station_id | Идентификатор погодной станции. |
| date | w.date | Дата измерения погоды. |
| temperature | w.temperature | Температура |
| humidity | w.humidity | Влажность воздуха |
| wind_speed | w.wind_speed | Скорость ветра |
На основе метеорологических данных рассчитывается эквивалентная температура, которая используется в качестве входных данных для регрессионного анализа.
37 - (37 - temperature) / (0.68 - 0.0014 * humidity] + 1 / (1.76 + 1.4 * pow(wind_speed, 0.75))) - 0.29 * temperature * (1 - humidity / 100)В этой формуле:
- Вычисляется разница между 37°C и фактической температурой: (37 - temperature). Это базовый "дефицит тепла".
- Вычисляется фактор сопротивления: (0.68 - 0.0014 * humidity + 1 / (1.76 + 1.4 * pow(wind_speed, 0.75))). Он увеличивается при высокой влажности (меньше охлаждения) и уменьшается при сильном ветре (больше охлаждения).
- Делится разница на фактор сопротивления и вычитается из 37: это даёт основную ощущаемую температуру с учетом конвекции.
- Вычитается корректировка на испарение: 0.29 * temperature * (1 - humidity / 100), которая дополнительно охлаждает в сухих условиях.
Календарные данные
В прогнозах используются данные производственного календаря из таблицы и календарь Православных Христианских праздников.
Ниже представлен запрос календарных данных:
SELECT
date,
type AS holiday
FROM calendar
WHERE date BETWEEN '{from_date}' AND '{to_date}'
ORDER BY date;Запрос берет значения из:
- calendar — табель-календарь, заполняемый через систему репликации
Запрос формирует следующие поля:
| Поле в SELECT | Исходное поле | Описание |
| date | date |
Дата календарного события |
|
holiday |
type |
Тип события |
Данные о православных праздниках хранятся в файле: calendar.csv
Расчёт требуемого количества сборщиков и курьеров
Логика расчета одинакова для сборщиков и курьеров. Прогноз трудоемкости автоматически преобразуется в требуемое количество сотрудников. Алгоритм включает следующие шаги:
1. Оценка скорости сборки сотрудников
Для каждого сотрудника рассчитывается средняя скорость сборки на основе фактических данных за последний месяц. Скорость измеряется в количестве строк заказов, собираемых за час. Расчет выполняется в преобразовании scheduleBindings, код которого хранится в БД приложения. Из представления time_series_col_hourly извлекается сумма собранных строк, деленная на общее количество часов работы. Учитываются только часы с продолжительностью сборки от 1000 до 3600 секунд, что исключает неполные или чрезмерно длинные интервалы и повышает надежность оценки.
$userStatAvgRaw := $query($tqueryQuery, {
'table': 'time_series_col_hourly',
'from': $userStatFrom,
'restaurantIds': $restaurantIds,
'query': [
{
'select': {
'user_id': 'user_id'
},
'sum': {
'sum_qty': 'qty'
},
'count': {
'cnt': '*'
},
'where': {
'len >=': 1000000,
'len <=': 3600000
}
}
]
});
$userStatAvg := $userStatAvgRaw.tquery{
$string(user_id): {
'speed': $number(sum_qty) / $number(cnt)
}
};2. Расчет плановой производительности
Далее для каждого часа прогнозируемого периода рассчитывается ожидаемое количество собранных строк на основе списка запланированных сборщиков и их индивидуальной скорости. Расчет выполняется в настройке dayPlaceTransform. Если дата относится к будущему, сотрудники фильтруются по позиции "Сборщик". Для каждого сотрудника извлекается индивидуальная скорость (userSpeed). Интервал события разбивается на часы; для каждого часа вклад рассчитывается как длительность работы × скорость / ~3,6 млн миллисекунд (для перевода в часы). Вклады суммируются в sum_qty для часа. В массиве $hours (0–23 часа) значение plan устанавливается как sum_qty (или 0 при отсутствии данных). Таким образом формируется плановая производительность — ожидаемое количество собранных строк заказов на основе текущего плана.
$eventsStat := $inPast
? $lookup($lookup($ttStat, $string(place.id)),$dateStr)
: $statEvents[position~>/Сборщик/].(
$userSpeed := [$lookup($users,$string(userId)).userSpeedAvg, $speed][$!=null][0];
$user := $lookup($users, $string(userId));
$event := $user.isActive ? $range(beginAt, endAt).intersect($day);
$event ? $array($event.snapTo('hour').by('hour')).(
$r := $.range('hour').intersect($event);
$r ? {'h':$.format('H'), 't': $r.diff()*$userSpeed/3599999}
);
){
h: { 'sum_qty': $round($sum(t)) }
};
$hours := [0..23].(
...
$plan := $number([$lookup($eventsStat, $string($)).sum_qty, 0][0]);
...
);3. Сравнение с прогнозом
Далее рассчитывается разность между прогнозируемым количеством строк на сборку и плановой производительностью. Этот шаг выполняется в настройке dayPlaceTransform. В массиве $hours для каждого часа извлекается прогнозное значение ($stat) и план ($plan). Если дата в будущем, разность ($delta) вычисляется как (прогноз - план) / средняя скорость сборки. Положительное значение указывает на нехватку сотрудников, отрицательное — на избыток. Если прогноз отсутствует, $delta устанавливается в 0, чтобы избежать ошибок в рекомендациях.
$hours := [0..23].(
$statObj := $lookup($hourStat, $string($));
$stat := $number($inPast ? $statObj.cnt : $statObj.cnt) * $extraNorm;
$plan := $number([$lookup($eventsStat, $string($)).sum_qty, 0][0]);
$delta := $stat
? $inPast
? $round($plan - $stat, 1)
: $round(($stat - $plan) / $speed)
: 0;
...
);4. Корректировка численности
Затем разность преобразуется в дополнительное или избыточное количество сотрудников с использованием средней скорости сборки по всей торговой точке. Эта скорость рассчитывается в scheduleBindings аналогично индивидуальной, но для всех сборщиков вместе. Из представления time_series_col_hourly извлекается сумма собранных строк с группировкой по торговой точке и времени, а также агрегированные метрики: суммы, средние и количество записей. Ограничения по секундам сборки здесь не применяются.
$ttStatRaw := $query($tqueryQuery, {
'table': 'time_series_col_hourly',
'from': $statFrom,
'to': $to,
'restaurantIds': $restaurantIds,
'query': [
{
'select': {
'restaurant_id': 'restaurant_id',
'tstamp': 'tstamp'
},
'avg': {
'avg_cnt': 'cnt',
'avg_qty': 'qty'
},
'sum': {
'sum_qty': 'qty',
'sum_cnt': 'cnt'
},
'count': {
'cnt': '*'
}
}
]
});
$ttStat := $ttStatRaw.tquery{
$string(restaurant_id): $.{
'time': $moment(tstamp),
'sum_cnt': sum_cnt,
'sum_qty': sum_qty,
'avg_cnt': avg_cnt,
'avg_qty': avg_qty,
'cnt': cnt
}{
time.format('YYYY-MM-DD'): ${time.format('H'): {
'sum_cnt': sum_cnt,
'sum_qty': sum_qty,
'avg_cnt': avg_cnt,
'avg_qty': avg_qty,
'cnt': cnt
}}
}
};5. Вывод итогового количества
Наконец, полученное число используется для формирования рекомендаций о том, сколько сотрудников добавить или убрать в конкретный час. Пороговые значения определяются в настройке dayPlaceTransform. В функции $formatRowPlan (применяемой для будущих дней) извлекается объект часа с разностью ($delta). На основе этого значения формируется текст рекомендации: если разность равна нулю, отображается "Норма" в зеленом цвете без изменений; если разность положительная, показывается "Нехватка X человек" в красном (X — значение разности, что означает необходимость добавить сотрудников); если разность отрицательная, отображается "Избыток X человек" в оранжевом (X — абсолютное значение разности, что предполагает возможность убрать сотрудников). Если данных нет, выводится сообщение "Нет данных".
$formatRowPlan := function($t) {(
$h := $hours[$t];
$info := $h.stat ? $h.plan & ' из ' & $h.stat : '-';
$span := $h.delta = 0
? ''
: $h.delta > 0
? $redSpan
: $amberSpan;
$spanEnd := $h.delta = 0
? ''
: '';
$span & $formatNumber($t, '00') & ':00 - ' & $formatNumber($t+1, '00') & ':00' & $spanEnd & ' |
' & $span & $info & $spanEnd & '
' &
($h.stat
? $h.delta = 0
? $greenBox & 'Норма'
: $h.delta > 0
? $redBox & 'Нехватка ' & $h.delta & ' чел.'
: $amberBox & 'Избыток ' & -$h.delta & ' чел.'
: 'Нет данных') & '
';
)};Формула расчета требуемого количества сборщиков или курьеров
Все вышеперечисленные шаги можно описать формулой, которая рассчитывает рекомендуемое общее количество работников, необходимое для обработки заказов в конкретный час.

Где:
t — Конкретный час, о котором идёт речь
Dt — Сколько заказов на доставку ожидается в этот час
Nt — Сколько людей уже поставили смену на этот час
![]() — Средняя скорость работы i-го человека, записавшегося в смену
— Средняя скорость работы i-го человека, записавшегося в смену
![]() — Средняя скорость по всем курьерам на точке
— Средняя скорость по всем курьерам на точке
Rt — Сколько работников нужно вывести в итоге в этот час
Аналитика сборки по прошедшим дням
Пользователю отображаются следующие элементы:
- Временной интервал, за который представлены данные;
- Прогнозное количество заказов для указанного интервала (ожидаемое значение, сформированное прогнозной моделью на основе данных, описанных в статье);
- Фактическое количество заказов за интервал (реальное значение, извлеченное из базы данных ВкусВилл);
- Оценка точности прогноза, рассчитываемая как симметричная средняя абсолютная процентная ошибка.
(2 * (факт - прогноз) / (факт + прогноз))
Возможные значения:
- "Попадание" (прогноз был в пределах нормы если разница между фактом и прогнозом меньше либо равна 3 или оценка точности < 0,15),
- "Недопрогноз" (прогноз был занижен, фактическое значение выше если оценка точности > 0),
- "Перепрогноз" (прогноз был завышен, фактическое значение ниже если оценка точности < 0)
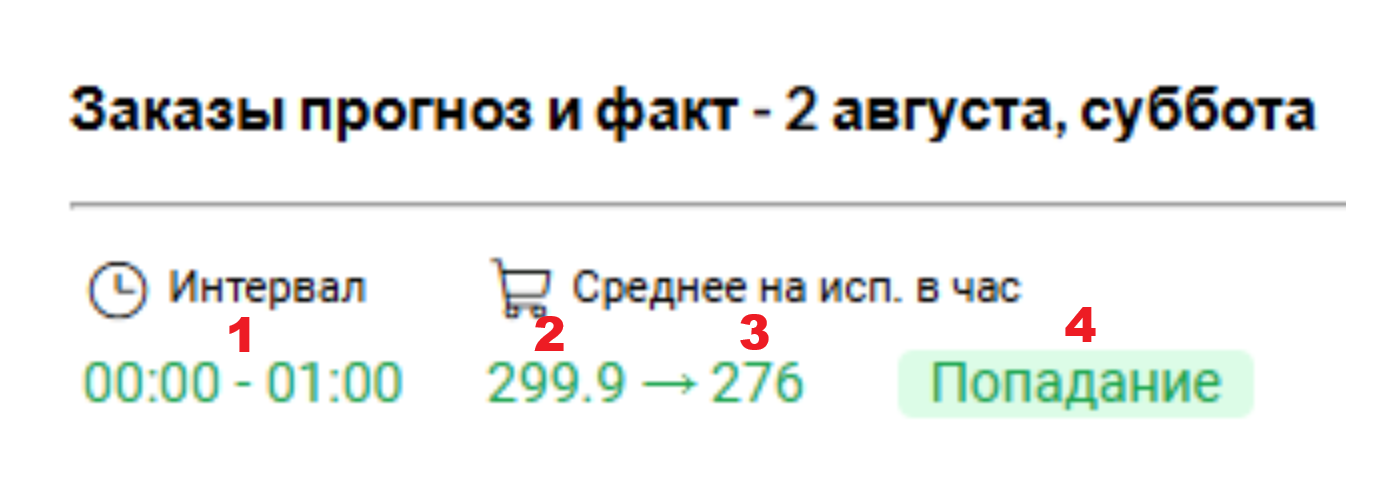
Прогнозное значение извлекается из таблицы time_series, из записей с типом 7 (обозначающим прогноз по геозонам для сборки заказов). Значение берется из поля value.

Фактическое значение формируется из представления time_series_col_hourly, которое создается на основе информации из таблицы time_series. Количество заказов рассчитывается путем суммирования значений поля qty всех записей за выбранный интервал. Пример расчета: для значений qty = 90 + 118 + 68 общее количество заказов составляет 276.

Для отображения всех этих данных в интерфейсе используется настройка dayPlaceTransform, которая формирует массив $hours. Массив содержит объекты для каждого часа суток (0–23) с соответствующими полями:
- hour — текущий час;
- stat — прогнозное количество заказов на этот час;
- plan — фактическое количество заказов на этот час;
- delta — отклонение между прогнозом и фактическим значением.
- smape — относительная ошибка прогноза, чтобы оценить его качество независимо от масштаба данных (симметричная средняя абсолютная процентная ошибка).
- err — ошибка прогноза: 0 — в пределах нормы (попадание), 1 — недопрогноз (прогноз занижен), -1 — перепрогноз (прогноз завышен).
Код, формирующий массив представлен ниже.
$hours := [0..23].(
$statObj := $lookup($hourStat, $string($));
$stat := $number($inPast ? $statObj.cnt : $statObj.cnt) * $extraNorm;
$plan := $number([$lookup($eventsStat, $string($)).sum_qty, 0][0]);
$delta := $stat
? $inPast
? $round($plan - $stat, 1)
: $round(($stat - $plan) / $speed)
: 0;
$smape := 2 * ($plan - $stat) / ($plan + $stat);
$err := ($abs($delta) <= 3 or $abs($smape) < 0.15)
? 0
: $smape > 0
? 1
: -1;
{
"hour": $,
"stat": $round($stat,1),
"plan": $round($plan,1),
"delta": $delta,
"smape": $smape,
"err": $err
};
);Аналитика сборки по будущим дням
Пользователю предоставляется следующая информация:
- Временной интервал, за который представлены данные;
- Покрываемое количество заказов для указанного интервала (основывается на списке запланированных сборщиков и их индивидуальной скорости работы; механизм расчета описан в статье, пункты 1 и 2);
- Прогнозное количество заказов за интервал (ожидаемое значение, сформированное прогнозной моделью на основе данных, описанных в статье);
- Оценка требуемого количества сборщиков (механизм расчета описан в статье); возможные значения:
- "Норма" (сотрудников достаточно для обработки ожидаемого количества заказов)
- "Избыток" (сотрудников запланировано больше необходимого, возможен простой персонала)
- "Нехватка" (сотрудников недостаточно для успешной обработки заказов).
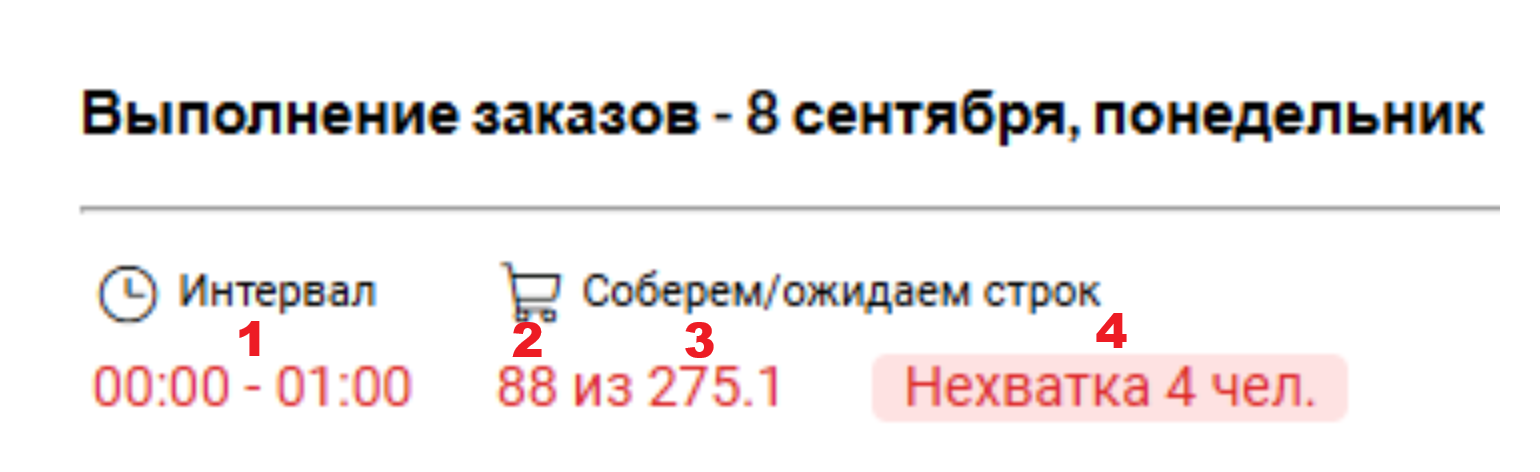
Прогнозное значение извлекается из таблицы time_series, из записей с типом 7 (обозначающим прогноз по геозонам для сборки заказов). Значение берется из поля value.

Покрываемое количество заказов рассчитывается в приложении через настройку dayPlaceTransform на основе данных о запланированных сотрудниках на час и их скорости сборки. При изменении числа сотрудников данные обновляются автоматически.
После расчета, эта настройка формирует массив $hours, содержащий данные для отображения в интерфейсе. Массив состоит из объектов для каждого часа суток (0–23), включающих поля:
- hour — текущий час;
- stat — прогнозное количество заказов;
- plan — покрываемое количество заказов, рассчитанное на основе сотрудников и скорости сборки;
Код, формирующий массив представлен ниже.
$hours := [0..23].(
$statObj := $lookup($hourStat, $string($));
$stat := $number($inPast ? $statObj.cnt : $statObj.cnt) * $extraNorm;
$plan := $number([$lookup($eventsStat, $string($)).sum_qty, 0][0]);
$delta := $stat
? $inPast
? $round($plan - $stat, 1)
: $round(($stat - $plan) / $speed)
: 0;
$smape := 2 * ($plan - $stat) / ($plan + $stat);
$err := ($abs($delta) <= 3 or $abs($smape) < 0.15)
? 0
: $smape > 0
? 1
: -1;
{
"hour": $,
"stat": $round($stat,1),
"plan": $round($plan,1),
"delta": $delta,
"smape": $smape,
"err": $err
};
);Так же, в таблице time_series в записях с типом 163 сохраняются данные, вычисляемые в базе данных по аналогичной схеме один раз в сутки и используемые для выгрузки.

Аналитика курьеров по прошедшим дням
Пользователю предоставляется следующая информация:
- Временной интервал, за который представлены данные;
- Прогнозное количество заказов для указанного интервала (ожидаемое значение, сформированное прогнозной моделью на основе данных, описанных в статье);
- Фактическое количество заказов за интервал (реальное значение, извлеченное из базы данных ВкусВилл);
- Оценка точности прогноза, рассчитываемая как симметричная средняя абсолютная процентная ошибка.
(2 * (факт - прогноз) / (факт + прогноз))
Возможные значения:
- "Попадание" (прогноз был в пределах нормы если разница между фактом и прогнозом меньше либо равна 3 или оценка точности < 0,15),
- "Недопрогноз" (прогноз был занижен, фактическое значение выше если оценка точности > 0),
- "Перепрогноз" (прогноз был завышен, фактическое значение ниже если оценка точности < 0)

Прогнозное значение извлекается из таблицы time_series, из записей с типом 6 (обозначающим прогноз по геозонам для доставки заказов). Значение берется из поля value.

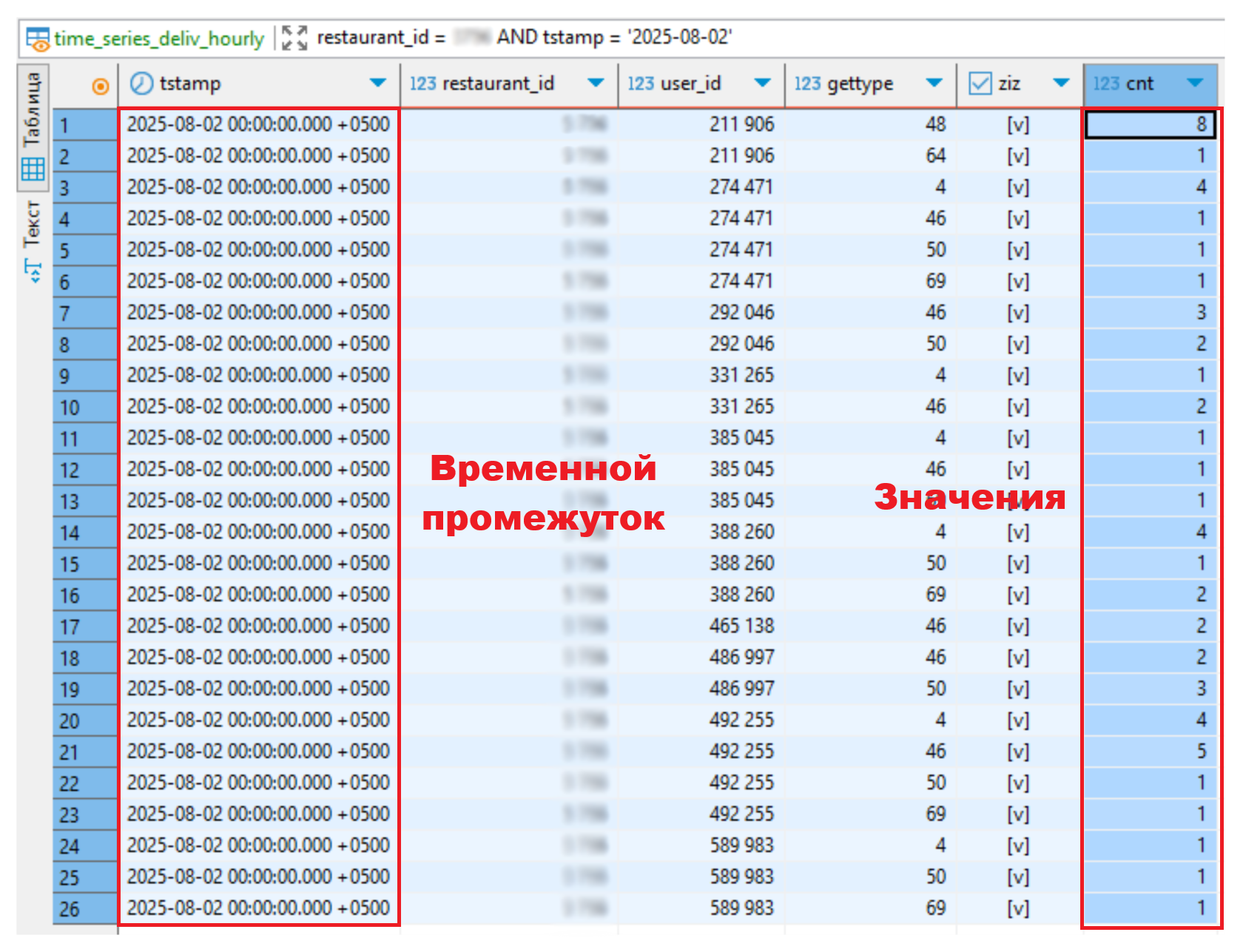
Фактическое значение рассчитывается из представления time_series_deliv_hourly, созданного на основе таблицы time_series и содержащего данные о заказах курьеров. Количество заказов определяется суммированием значений поля cnt (количество доставленных заказов) всех записей за выбранный интервал. Пример: для интервала 00:00–01:00 2 августа сумма значений cnt (8 + 1 + 4 + 1 + 1 + 1 + 3 + 2 + 1 + 2 + 1 + 1 + 1 + 4 + 1 + 2 + 2 + 2 + 3 + 4 + 5 + 1 + 1 + 1 + 1 + 1) равна 55.
Для отображения всех этих данных в интерфейсе используется настройка dayPlaceTransform, которая формирует массив $hours. Массив содержит объекты для каждого часа суток (0–23) с соответствующими полями:
- hour — текущий час;
- stat — прогнозное количество заказов на этот час;
- plan — фактическое количество заказов на этот час;
- delta — отклонение между прогнозом и фактическим значением.
- smape — относительная ошибка прогноза, чтобы оценить его качество независимо от масштаба данных (симметричная средняя абсолютная процентная ошибка).
- err — ошибка прогноза: 0 — в пределах нормы (попадание), 1 — недопрогноз (прогноз занижен), -1 — перепрогноз (прогноз завышен).
Код, формирующий массив представлен ниже.
$hours := [0..23].(
$statObj := $lookup($hourStat, $string($));
$stat := $number($inPast ? $statObj.cnt : $statObj.cnt) * $extraNorm;
$plan := $number([$lookup($eventsStat, $string($)).sum_qty, 0][0]);
$delta := $stat
? $inPast
? $round($plan - $stat, 1)
: $round(($stat - $plan) / $speed)
: 0;
$smape := 2 * ($plan - $stat) / ($plan + $stat);
$err := ($abs($delta) <= 3 or $abs($smape) < 0.15)
? 0
: $smape > 0
? 1
: -1;
{
"hour": $,
"stat": $round($stat,1),
"plan": $round($plan,1),
"delta": $delta,
"smape": $smape,
"err": $err
};
)Аналитика курьеров по будущим дням
Пользователю предоставляется следующая информация:
- Временной интервал, за который представлены данные;
- Покрываемое количество заказов для указанного интервала (основывается на списке запланированных сборщиков и их индивидуальной скорости работы; механизм расчета описан в статье, пункты 1 и 2);
- Прогнозное количество заказов за интервал (ожидаемое значение, сформированное прогнозной моделью на основе данных, описанных в статье);
- Оценка требуемого количества сборщиков (механизм расчета описан в статье); возможные значения:
- "Норма" (сотрудников достаточно для обработки ожидаемого количества заказов)
- "Избыток" (сотрудников запланировано больше необходимого, возможен простой персонала)
- "Нехватка" (сотрудников недостаточно для успешной обработки заказов).
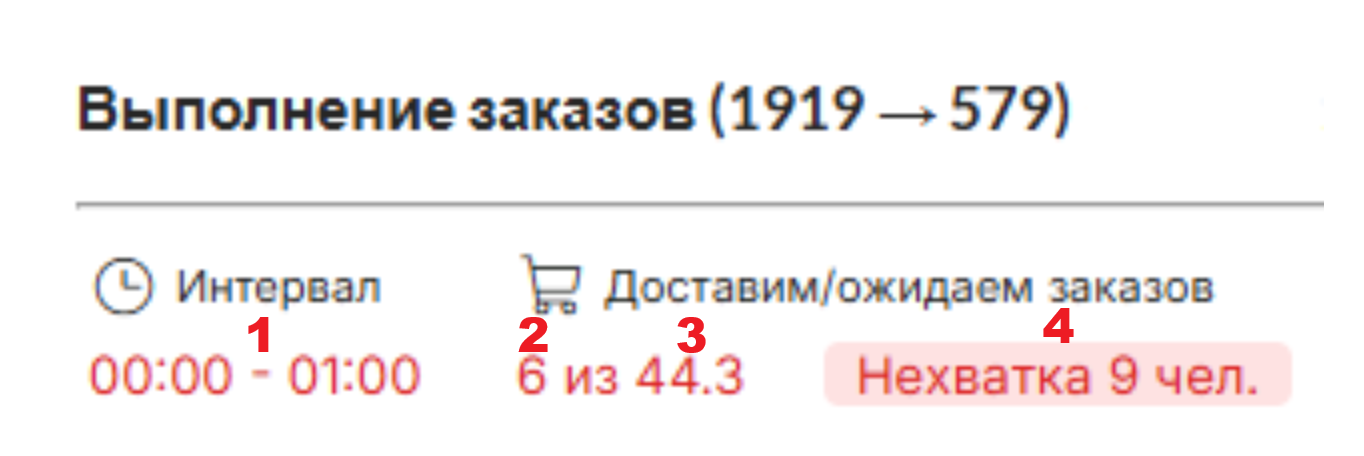
Прогнозное значение извлекается из таблицы time_series, из записей с типом 6 (обозначающим прогноз по геозонам для доставки заказов). Значение берется из поля value.

Покрываемое количество заказов рассчитывается в приложении через настройку dayPlaceTransform на основе данных о запланированных сотрудниках на час и их скорости сборки. При изменении числа сотрудников данные обновляются автоматически.
После расчета, эта настройка формирует массив $hours, содержащий данные для отображения в интерфейсе. Массив состоит из объектов для каждого часа суток (0–23), включающих поля:
- hour — текущий час;
- stat — прогнозное количество заказов;
- plan — покрываемое количество заказов, рассчитанное на основе сотрудников и скорости сборки;
Код, формирующий массив представлен ниже.
$hours := [0..23].(
$statObj := $lookup($hourStat, $string($));
$stat := $number($inPast ? $statObj.cnt : $statObj.cnt) * $extraNorm;
$plan := $number([$lookup($eventsStat, $string($)).sum_qty, 0][0]);
$delta := $stat
? $inPast
? $round($plan - $stat, 1)
: $round(($stat - $plan) / $speed)
: 0;
$smape := 2 * ($plan - $stat) / ($plan + $stat);
$err := ($abs($delta) <= 3 or $abs($smape) < 0.15)
? 0
: $smape > 0
? 1
: -1;
{
"hour": $,
"stat": $round($stat,1),
"plan": $round($plan,1),
"delta": $delta,
"smape": $smape,
"err": $err
};
);
Таблица плановых и фактических курьеров
В интерфейсе отображаются следующие данные за выбранный день:
- Количество запланированных курьеров: Учитываются курьеры, чьи выходы были назначены заранее (до наступления дня). Данные извлекаются из списка запланированных сотрудников, фильтруются по курьерам и разбиваются по типам (Авто, Вело, Вело Свой, Ночной Вело, Ночной Авто, Мобильный Авто и т.д.).
- Количество фактически отработавших на смене: Учитываются курьеры, которые реально работали в этот день и у которых проставлен соответствующий выход в приложении. Это определяется по информации которая приходит извне из приложения ПМ Курьер. Для будущих дней значение всегда равно нулю, поскольку день еще не наступил.
- Процент вакцинированных: Рассчитывается на основе списка запланированных или фактически вышедших курьеров. Определяется доля сотрудников с активным статусом вакцинации среди общего количества в списке.

Значения рассчитываются динамически исходя из текущего графика. При изменении графика данные обновляются в реальном времени.