Логика прогнозов
Прогноз для последней мили:
Прогнозы по сборке и доставке строятся с шагом 1 час и охватывают период в 14 дней вперёд.
Обычный прогноз.
Основан на данных о сборке и доставке, где каждый заказ привязан к ТТ.
Данные загружаются в БД Ally из БД MS SQL через Node-RED.
Зональный прогноз.
Основан на данных о сборке и доставке, где каждый заказ привязан к ТТ, и на статистике распределения адресов по зонам той или иной ТТ.
На основе геозон ТТ формируются сводные буферы, по которым рассчитываются вероятности выполнения заказов конкретной ТТ, исходя из статистики за последние 7 дней.
Вся история заказов автоматически сопоставляется с текущими геозонами, что позволяет обучать модель так, как будто эти зоны всегда были такими. Это также даёт возможность строить прогнозы для новых ТТ с недостаточной историей данных.
Прогноз для розницы
Прогноз по трудоёмкости строится с шагом 1 день и охватывает 21 день вперёд.
Основан на оценке трудоёмкости, которая загружается во временной ряд 51 через Node-RED.
Расчёт требуемого количества сборщиков и курьеров
Логика расчета идентична для сборщиков и курьеров. Прогноз трудоёемкости сборщиков автоматически пересчитывобразуется в требуемое количество сботрщудников. РасчёАлгоритм выпоклняючается по следующиему шалгоритму:
- Оценка скорости сборки сотрудников
ДСначала для каждого сотрудника рассчитывается средняя скорость сборки на основе фактических данных за последний месяц.
СЭта скоростьвыизмеражаяется в количестве строк заказов, которые сотрудник может собираетьвза час. - Расч
ёет происходит в преобразовании scheduleBindings, код которого хранится в базе данных приложения. В процессе из представления time_series_col_hourly извлекается сумма собранных строк за период, и это значение делится на общее количество часов работы. Чтобы обеспечить максимальную корректность, учитываются только часы, в которых сотрудник занимался сборкой от 1000 до 3600 секунд. Это позволяет исключить неполные или чрезмерно длинные интервалы, делая оценку более надежной.$userStatAvgRaw := $query($tqueryQuery, { 'table': 'time_series_col_hourly', 'from': $userStatFrom, 'restaurantIds': $restaurantIds, 'query': [ { 'select': { 'user_id': 'user_id' }, 'sum': { 'sum_qty': 'qty' }, 'count': { 'cnt': '*' }, 'where': { 'len >=': 1000000, 'len <=': 3600000 } } ] }); $userStatAvg := $userStatAvgRaw.tquery{ $string(user_id): { 'speed': $number(sum_qty) / $number(cnt) } };2. Расчет плановой производительности
Далее для каждого часа прогнозируемого периода
рассвычитывасляется ожидаемое количество собранных строк.наЭто основывается на спискае запланированных сборщиков и их индивидуальной скорости работы. - Сам расчет выполняется в настройке dayPlaceTransform. Если дата для расчета относится к будущему, события сотрудников сначала фильтруются по позиции "Сборщик", чтобы учесть только сборщиков. Затем для каждого события извлекается индивидуальная скорость — userSpeed. Временной интервал события разбивается на часы, и для каждого часа рассчитывается вклад: длительность работы в этом часе умножается на скорость и делится на приблизительно 3,6 миллиона миллисекунд (для перевода в часы). Эти вклады суммируются в значение sum_qty для часа. В итоге в массиве $hours, который охватывает 0–23 часа, значение plan устанавливается как sum_qty для соответствующего часа или как 0, если данных нет. Таким образом формируется плановая производительность — то, сколько строк заказов ожидается собрать на основе текущего плана.
$eventsStat := $inPast ? $lookup($lookup($ttStat, $string(place.id)),$dateStr) : $statEvents[position~>/Сборщик/].( $userSpeed := [$lookup($users,$string(userId)).userSpeedAvg, $speed][$!=null][0]; $user := $lookup($users, $string(userId)); $event := $user.isActive ? $range(beginAt, endAt).intersect($day); $event ? $array($event.snapTo('hour').by('hour')).( $r := $.range('hour').intersect($event); $r ? {'h':$.format('H'), 't': $r.diff()*$userSpeed/3599999} ); ){ h: { 'sum_qty': $round($sum(t)) } }; $hours := [0..23].( ... $plan := $number([$lookup($eventsStat, $string($)).sum_qty, 0][0]); ... );3. Сравнение с прогнозом
ВыПосле этого рассчи
слятывается разность между прогнозируемым количеством строк на сборку и плановой производительностью. Этот шаг также выполняется в настройке dayPlaceTransform. В массиве $hours для каждого часа извлекается прогнозное значение ($stat) и план ($plan). Если дата расчета в будущем, разность ($delta) вычисляется как (прогноз - план) / среднюю скорость сборщки. Положительное значение указывает на нехватку сотрудников, отрицательное — на избыток. - Если прогноз отсутствует, $delta устанавливается в 0, чтобы избежать ошибок в дальнейших рекомендациях.
$hours := [0..23].( $statObj := $lookup($hourStat, $string($)); $stat := $number($inPast ? $statObj.cnt : $statObj.cnt) * $extraNorm; $plan := $number([$lookup($eventsStat, $string($)).sum_qty, 0][0]); $delta := $stat ? $inPast ? $round($plan - $stat, 1) : $round(($stat - $plan) / $speed) : 0; ... );4. Корректировка численности
РЗатем разность преобразуется в дополнительное или избыточное количество сотрудников. Для этого используется средняя скорость сборки по все
м сборщикам на данной торговой точке, которая рассчитывается в scheduleBindings аналогично индивидуальной скорости, но для всех сборщиков вместе. - Из представления time_series_col_hourly извлекается сумма собранных строк с группировкой по торговой точке и времени, а также рассчитываются агрегированные метрики: суммы, средние и количество записей. Ограничения по секундам сборки здесь не применяются.
$ttStatRaw := $query($tqueryQuery, { 'table': 'time_series_col_hourly', 'from': $statFrom, 'to': $to, 'restaurantIds': $restaurantIds, 'query': [ { 'select': { 'restaurant_id': 'restaurant_id', 'tstamp': 'tstamp' }, 'avg': { 'avg_cnt': 'cnt', 'avg_qty': 'qty' }, 'sum': { 'sum_qty': 'qty', 'sum_cnt': 'cnt' }, 'count': { 'cnt': '*' } } ] }); $ttStat := $ttStatRaw.tquery{ $string(restaurant_id): $.{ 'time': $moment(tstamp), 'sum_cnt': sum_cnt, 'sum_qty': sum_qty, 'avg_cnt': avg_cnt, 'avg_qty': avg_qty, 'cnt': cnt }{ time.format('YYYY-MM-DD'): ${time.format('H'): { 'sum_cnt': sum_cnt, 'sum_qty': sum_qty, 'avg_cnt': avg_cnt, 'avg_qty': avg_qty, 'cnt': cnt }} } };5. Вывод итогового количества
ПНаконец, полученное число используется для формирования рекомендаций
:о том, сколько сотрудниковнеобходимодобавить или убратьиз сменыв конкретный час.
1.
Для подсчета скПорости сбгоркивые знаказчения ов испоредельзуеяются подходв насредней скотростйке dayPlaceTransform. В функции сборки$formatRowPlan, которая применяется для будущих дней, извлекается объект часа с разностью ($delta). На основе этого значения формируется текст рекомендации: если разность равна нулю, отображается "Норма" в зеленом цвете без каких-либо изменений; если разность положительная, показывается "Нехватка X человек" в краснолим, где X — это значение разности, что означает необходимость добавоить сотрудников; если разность отрицательная, отображается "Избыток X человек" в оранжевом, где X — абсолютное значение разности, что предполагает возможность убрать сотрудников. Если данных снетрок, выводится течсообщение "Нет данных".
$formatRowPlan := function($t) {(
$h := $hours[$t];
$info := $h.stat ? $h.plan & ' из ' & $h.stat : '-';
$span := $h.delta = 0
? ''
: $h.delta > 0
? $redSpan
: $amberSpan;
$spanEnd := $h.delta = 0
? ''
: '';
$span & $formatNumber($t, '00') & ':00 - ' & $formatNumber($t+1, '00') & ':00' & $spanEnd & ' |
' & $span & $info & $spanEnd & '
' &
($h.stat
? $h.delta = 0
? $greenBox & 'Нодногорма'
: $h.delta > 0
? $redBox & 'Нехватка ' & $h.delta & ' чел.'
: $amberBox & 'Избыток ' & -$h.delta & ' чел.'
: 'Нет даснных') & '
';
)};Формула (строки / час).
Расчета требуемого количества сборщиков или курьеров
Прогноз по требуемому количеству сборщиков или курьеров можно описать формулой:, которая рассчитывает рекомендуемое общее количество работников, необходимое для обработки заказов в конкретный час.
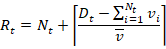
Где:
t — Конкретный час, о котором идёт речь
Dt — Сколько заказов на доставку ожидается в этот час
Nt — Сколько людей уже поставили смену на этот час
![]() — Средняя скорость работы i-го человека, записавшегося в смену
— Средняя скорость работы i-го человека, записавшегося в смену
![]() — Средняя скорость по всем курьерам на точке
— Средняя скорость по всем курьерам на точке
Rt — Сколько работников нужно вывести в итоге в этот час